
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 스테레오비전
- 이진논리
- 시그모이드
- 다항논리
- 코테준비
- 생존신고
- 겟레디윗미
- 머신러닝
- 스파르타코딩클럽
- algorithm jobs
- 새싹개발자
- python 코테
- 가장쉽게배우는머신러닝
- 딥러닝역사
- coding test
- 스파르타코딩
- tstory 첫포스팅
- 진도사우르스
- 블렌디드러닝
- 코랩
- 코테연습
- 개발일지
- 취뽀기원
- 로지스틱회귀
- 포스코아카데미
- 산학대전
- 딥러닝
- 라즈베리파이란
- 캐글
- 라즈베리파이사용법
- Today
- Total
동에 번쩍, 서에 번쩍
[스파르타 코딩클럽] 가장 쉽게 배우는 머신러닝 3주차 개발일지 본문

2주차 개발일지를 올린지
4시간 만에 올리게된 3주차 개발일지...ㅠㅠ
종강을 너무 만끽한 탓에 수업을 밀려버려
진도 사우르스에게 잡히고 말았도다 허허
사실 겟레디윗미 참가기념 굿즈도 한참전에 받았는데
포스팅도 아직 안함 ㅎㅎㅎㅎ
우선 밀린 강의 수강하고 차차 올리도록 하겠다..!
3주차에는 딥러닝에 대해 학습했다.
전공수업때 들었던 머신러닝 과목은 전반적인 이론에 대해
자세하게 배우느라, 인공지능 과목은
파이썬 기초부터 회귀와 분류에 대해 집중하느라
신경망 부분에 대해서 실습과 과제는
별로 진행되지 않았기에
딥러닝에 대해서는 구현을 해보지 않아
아쉬움이 있던 영역이었다!
(진행됐다해도 컴퓨터가 못따라왔겠지만 ㅎㅎ;)
그래서 3주차는 더욱 더 꼼꼼히 들었던 것 같다!
(그렇다고 1, 2주차 수업 대충 들은 것은 아님X!!)
튜터님도 실무에서 사용하는 모든 것을
강의자료에 녹여내기 위해서 딥러닝 관련
강의자료에 대해 엄청 준비하셨다고 말씀하셨는데
그림자료부터 이것저것 구성이 알찼다!
1. 딥러닝의 역사

앞서 2주차에서 나왔던 로지스틱 회귀처럼
실제 자연계에는 선형으로 풀 수 있는 문제들이
많지 않았고 처음에는 위 사진처럼 선형회귀를 여러번
반복해서 풀이를 진행했다고 한다.

하지만 선형회귀를 반복한다고 해서
비선형의 특성을 갖는 것은 아니기에 반복되는
선형회귀 사이에 비선형의 무언가를
넣어야 한다고 생각했고, 위 사진처럼 층(Layer)을
여러개 쌓아 만들어낸 모델의 결과가
뛰어나자 층을 깊게 쌓는다고 해서
딥러닝(Deep Learning)이라고 불리게 되었다고 한다!

또한 딥러닝이 나오게 된 배경에는
논리 게이트 XOR 문제를 해결하기 위해서도 있다.
AND와 OR은 위 사진처럼
하나의 직선으로 해결할 수 있고,

그 직선은 우리가 잘 알고있는
논리 회귀로 만들 수 있다.
위의 수식을 다음과 같은 그림으로
다시 표현할 수 있고 이를 Perceptron(퍼셉트론)이라고칭하였다.

이처럼 w0, w1, w2의 값만 잘 지정한다면
우리가 원하는 출력을 계산할 수 있었기 때문에 사람들은
"AND, OR 조합으로 생각하는 기계를 만들 수 있다!!"
라고 생각했고 실제로 1958년 뉴욕 타임즈에는
아래와 같은 루머가 실제로 실렸다고 한다.

1958년에 이런 생각을 했다는 것이
정말정말 놀라울 따름..!!

하지만! 이는 루머에 불과했던 것이
바로 XOR문제는 직선 하나로 풀 수 없다는 것..!
따라서 퍼셉트론을 여러개 붙인 MLP라는 개념을
도입해서 문제를 풀어보고자 하였으나

너무 많은 연산량을 필요로 하기에
당시의 기술로는 불가능하다고
세계적으로 저명한 Minsky 박사가
논문을 통해 증명해내었고
MLP를 현실적으로 구현하기 위해서
20년 정도 후퇴하게 된다..!
위와 같은 이유로 지속되던
딥러닝의 침체기는 1974년에 발표된
Paul Werbos 박사의 Backpropagation Algorithm이 등장하며
와장창 깨지게 되었는데 폴 박사는
다음 세개의 주장을 펼쳤다.

1. 우리는 W(weight)와 b(bias)를
이용해서 주어진 입력을 가지고 출력을 만들어 낼 수 있다.
2. 그런데 MLP가 만들어낸 출력이
정답값과 다를 경우 W와 b를 조절해야한다.
3.그것을 조절하는 가장 좋은 방법은 출력에서
Error(오차)를 발견하여 뒤에서 앞으로
점차 조절하는 방법이 필요하다.
무슨말인지 모르겠다구여?
괜찮아요. 저도 잘 ㅁ...은 아니고
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
음 한마디로 피드백을 이용한것인데 이전의 알고리즘들은
앞의 Layer부터 순차적으로 연산되는
Forward 방식이었다면, 이는 Output Layer부터
Chain Rule(연쇄법칙)을 이용하여 연산을 시작하여
가중치를 업데이트해가며 학습을 진행하는 알고리즘이다!
이정도는 완전 가볍게 설명한 내용이라
만약에 Backpropagation이 이해가 잘 안간다면
인터넷에 자세히 분석해 놓은 포스팅들이 있으니
찾아보는 것이 좋을듯하다!
(그냥 넘기기엔 무척 중요한 알고리즘이니까~!)
2. 딥러닝의 주요 개념
우선 딥러닝 학습에 주로 사용되는
단어들을 살펴보면

전제조건 : 1,000개의 데이터셋을 가짐
(아래 뜻 설명有)
1. Batch
: 수 많은 데이터셋을 한번에 학습시키기에는
컴퓨터가 버티기 힘드므로
작은 단위로 쪼개서 학습을 진행하는데
이때 쪼개는 단위(=100개)
2. Iteration
: 앞서 Batch size를 100개로 정하였다면
총 10번 반복하여야
모든 데이터셋을 학습시킬 수 있는데
이때 반복되는 횟수(=10번)
3. Epoch
: 보통 머신러닝에서 학습 시,
같은 데이터셋을 여러번 반복 학습시키는데
이때 반복학습이 진행되는 횟수(=정하기 나름)

4. Activation Fuctions
: 뇌의 뉴런이 다음 뉴런으로 전달할 때 보내는
전기신호의 특성에서 영감을 받아 만들어진 함수로
특정 임계치(Threshhold)를 넘어야다음 뉴런을 활성화 시킴
활성화 함수 = 비선형 함수!
(참고) 요즘 대부분 ReLU를 기본으로 쓰지만
여러 함수를 교체하며 정확도를 높여나가는 작업 필수
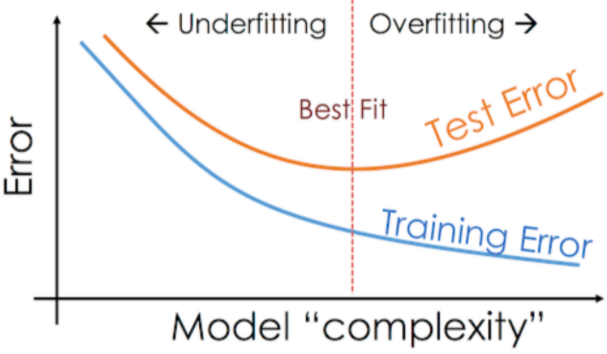
5. Overfitting
: Layer를 증가시키며 모델을 학습하다보면
Training Error는 낮아지는데,
반면에 Test Error는 올라가는 현상
이는 풀고자하는 문제보다 모델의 복잡도가 높거나
데이터셋이 부족할 때 발생!
6. Underfitting
: Overfitting과 반대로 풀고자하는
문제에 비해서 모델의 복잡도가 낮을 때 발생
3. 딥러닝의 주요 스킬
앞서 배웠던 Overfitting을 해결할 수 있는
방법들에 대해서도 학습했다.
현재 졸작에서 객체검출 알고리즘인 Yolo를
커스텀마이징해서 사용하고자하는데
오버피팅으로 인해 넣는 사진 족족
버스라고 인식하는 문제가 발생하는데
우리에게 주어진 문제는
누가봐도 데!이!터!셋! 부족!!이기에
사진을 긁어모으던가.. 구현을 다른 방식으로 하는 것을
알아보는중..^^ 무튼 처해진 상황에 대한
솔루션이다보니 더욱 귀가 쫑긋 했다고함..ㅎㅎ

1. Data augmentation
: 데이터의 갯수 늘리기
진짜 데이터=엄청난 돈 인것을 다들 알 것(?)일 텐데
사람의 눈으로 위 사진들을 봤을 때
약간의 차이들은 존재하지만
누가봐도 전부 사자이기에 이처럼 가지고 있는
데이터를 약간 변형하여 데이터셋을 늘리는 꼼수방법!!
2. Dropout
: 사공이 많으면 배가 산으로 간다
라는 말이 있듯이
하나의 결과를 도출하기 위해 너무 많은
노드가 있으면 결과가 오히려 떨어짐!
따라서 적당히 노드들을 탈락시켜서
더 좋은 효과를 내도록 하는것!
3. Ensenble
: 좋은 애들 + 좋은 애들 => 좋은 애들이겠지?
이것은 컴퓨터가 고사양일 때 사용할 수 있는 방법으로
여러개의 딥러닝 모델을 각각 학습시킨 후
출력을 기반으로 투표를 진행하는 기법!
Random forest와 유사하나 약간의 차이는 존재하는
그런 방법임!
4. 실습
이번 3주차에 진행된 실습은
딥러닝이 도출된 배경인 XOR 실습과
Sign Language MNIST 데이터셋을 통해
직접 딥러닝 모델을 학습시키고,
과제로는 MNIST 데이터셋을 이용해
딥러닝 모델을 구현해보는 것이었다.
이전에 전공과목에서도 MNIST를 이용하여
글씨체 인식하는 모델을 구현해봤는데
그때도 신기했는데 지금 다시해봐도 신기했다.
이번 과제 역시 수업을 잘 따라왔고,
코드사이의 관계만 잘 알고 있다면
복붙+수정으로 해결할 수 있을 과제였다!
더욱 알고싶던 영역이기도 했고,
이전과 비슷한 시간의 강의였지만
새로운 내용들이 많았기에
포스팅도 무척 길어졌..ㅎㅎㅎ
무튼 3주차 강의도 끝!
내일은 드디어 마지막 강의이기도 하고
진도 사우르스에게 잡히지 않도록
4주차 강의를 수강하고
개발일지로 찾아오도록 하겠..다!

Good Bye~
'다오니의 소소한 일상👀 > 스파르타 코딩클럽' 카테고리의 다른 글
| [스파르타 코딩클럽] 가장 쉽게 배우는 머신러닝 4주차 개발일지 (0) | 2021.07.14 |
|---|---|
| [스파르타 코딩클럽] 가장 쉽게 배우는 머신러닝 2주차 개발일지 (0) | 2021.06.28 |
| [스파르타 코딩클럽] 가장 쉽게 배우는 머신러닝 1주차 개발일지 (0) | 2021.06.09 |
| [스파르타 코딩클럽] 가장 쉽게 배우는 머신러닝 0주차 및 겟레디윗미 (GRWM:Get Ready With Me) 후기 (0) | 2021.06.07 |



